
Applications can do a lot of things, and among them, they can also enhance the way the network layer works. In this article, we will cover some important application layer protocols for the network. They are used to ease the network configuration, make the network resilient to faults, or help administrators in the initial setup of networking devices. The information you find in this article are a must-have for any networking technician, so enjoy the reading!
Protocols for the network: Network Layer is not enough
We all know the true purpose of the network layer: deliver packets to remote hosts. This is a simple statement that defines extremely well what the network layer does and is intended to do. To maintain modularity and scalability of the entire OSI stack, we must keep it this way. However, since the network layer is so limited by definition, we need to create some specific application-layer protocols to improve what happens at the network layer. Specifically, we are looking for some benefits that the network layer does not have by default.
The first thing we want is automation. We want things to be plug-and-play, reducing the configuration that the administrator needs to do. Then, we want to increase flexibility so that the network (intended as a set of devices) can recognize modifications and adapt to the new changes without human intervention. We also want ease of use, keeping the end-user experience as simple as possible. To do all of that, we have several protocols, but the most important are DNS and DHCP. We will treat them in this article, and then we will also have a brief overview of TFTP and Dynamic Routing.
DNS
DNS stands for Domain Name System, and it is a protocol that provides the translation between names and IP addresses. Any server on the Internet has an IP address, but it is extremely rare that you use IP addresses to navigate to the website you need. It would be impossible to remember them all. Instead, you use names: you know you navigate to google.com, not to 216.58.205.78. However, since the computer needs to know the IP address to send the traffic too, we cannot use names alone: that’s where the DNS comes in. Basically, a client asks to a DNS server “What is the IP address of this website?” and receives an answer containing that IP address.

DNS can works over UDP port 53 (server-side) by default, but can also use TCP port 53 in case the traffic goes over a low-quality link or in case the response contains a lot of information. DNS is based on two messages, queries (by the client) and responses (by the server). Each computer is configured with the IP address of a DNS server, and it will contact that server for any DNS query it has to do.
However, the Internet is a huge place, and no server can know everything about it. Instead, names are divided into DNS Zones, each zone managed by a set of servers. At the root of the Internet, we have a zone named “.” (dot), which is handled by the root DNS servers, managing the backbone of the Internet. In real-world operation, you contact one of them, which do not know exactly what is the IP address of the website you are looking for. Instead, it knows about a more specific DNS managing this zone. Then, the client will contact that other DNS dynamically. In this process, it will be redirected again and again, and eventually, it will contact the DNS server that knows the information about the website we were looking for.
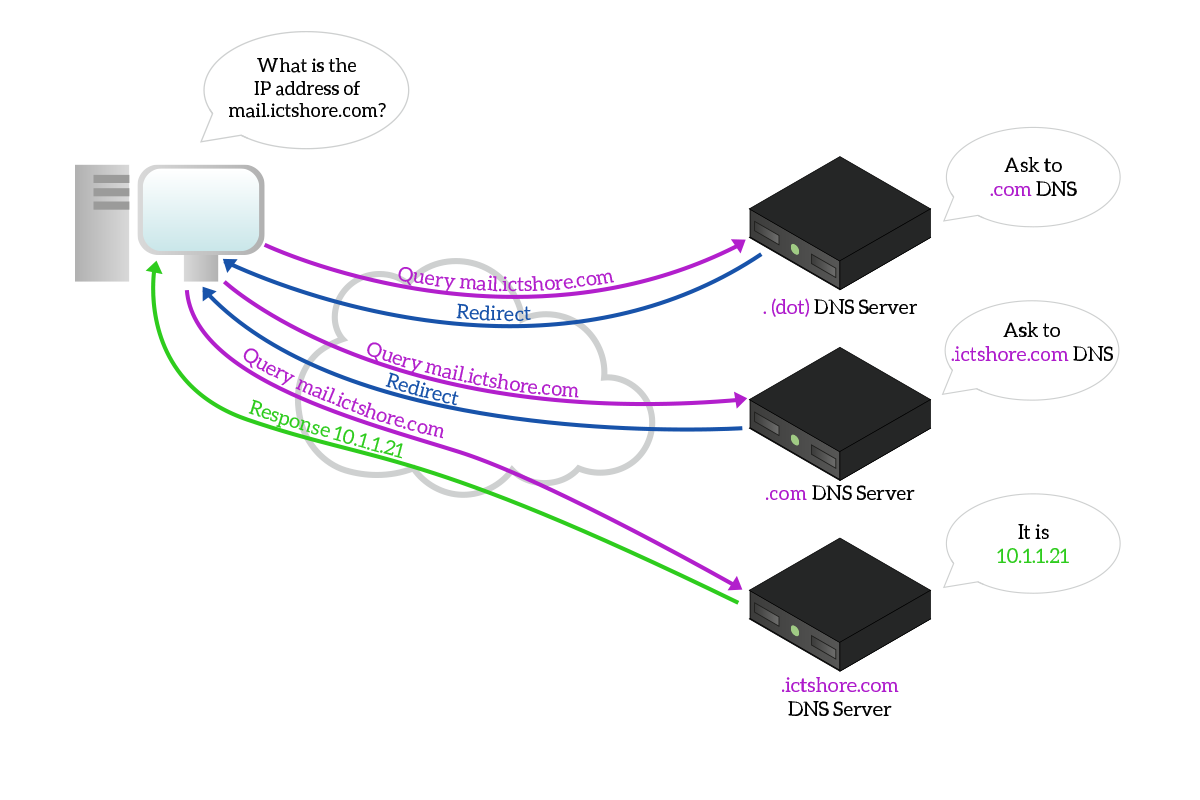
Let’s take a moment to explain the picture, so that we truly understand this concept. The client contacts the . (dot) DNS server asking for mail.ictshore.com. The server does not know the IP address of this website, but it knows it is part of the .com zone, so it tells the client the IP address of a server managing the .com zone. The client performs the same query to the .com DNS server, which do not know exactly what is the IP address of mail.ictshore.com, but it knows about a server managing .ictshore.com, so it tells the client this server’s IP address. The client tries again, contacting this newly discovered .ictshore.com DNS server.
This time, the DNS server knows the IP address of the target name, so it responds with the IP address the client was looking for. Note that the next time the client will start again from the . (dot) DNS server is the one it has in its configuration.
The dot DNS zone is the Internet root, or level zero. Then, each part you add adds a level. For example, .com is a first-level domain, while .ictshore.com is a second-level domain. The name of a website or server, with all its parent domains (as an example, server1.ictshore.com) is called Fully Qualified Domain Name (FQDN).
Another (uncommon) option is Recursive DNS. With this special configuration, the client makes queries to a DNS server which, instead of redirecting the client to the right zone, performs other queries to other DNS servers and, after that, returns the final IP address to the client. It is hard to find this configuration in the real-world. In fact, you should avoid it for two main reasons. First, an attacker could easily overwhelm the DNS server asking to perform a huge workload of queries; second, the server may take some time to perform all the queries and within that time the client may timeout the connection.
Both DNS servers and clients store DNS information. Specifically, the DNS client just remembers the final binding between the name and IP address and keeps it for minutes or hours before having to re-do the query again. The DNS server, instead, has a complex database that can be compared to a table with several records of different types. A DNS Record can be one of the types specified in the following table.
| Type ID | Type Name | Description |
|---|---|---|
| 1 | A | This record is the standard record, it associates a name to an IPv4 address. |
| 2 | NS | This record redirects to another DNS server. |
| 28 | AAAA | This record associates a name to an IPv6 address. |
| 15 | MX | This record associates a name to a message transfer agent (used to solve email addresses). |
| 5 | CNAME | This record associates a name to another name\, the client will continue to do queries for the new name returned. |
There are many other DNS Record types, but for the purpose of this article, these five types are more than enough. Generally, DNS servers are not managed by people managing the network infrastructure: they are managed by people managing infrastructure servers, so this knowledge is the one you need to work with DNS as a network technician.
DHCP
DHCP stands for Dynamic Host Configuration Protocol and does what the name says: it configures clients. Specifically, DHCP is the protocol used to assign IP addresses to clients automatically. Furthermore, you use it to give them other information useful to use the network (such as default gateway or DNS server). For this protocol, the client does not use a random port unlike may other protocols. Instead, it uses UDP port 68, while the server is always listening on port 67.
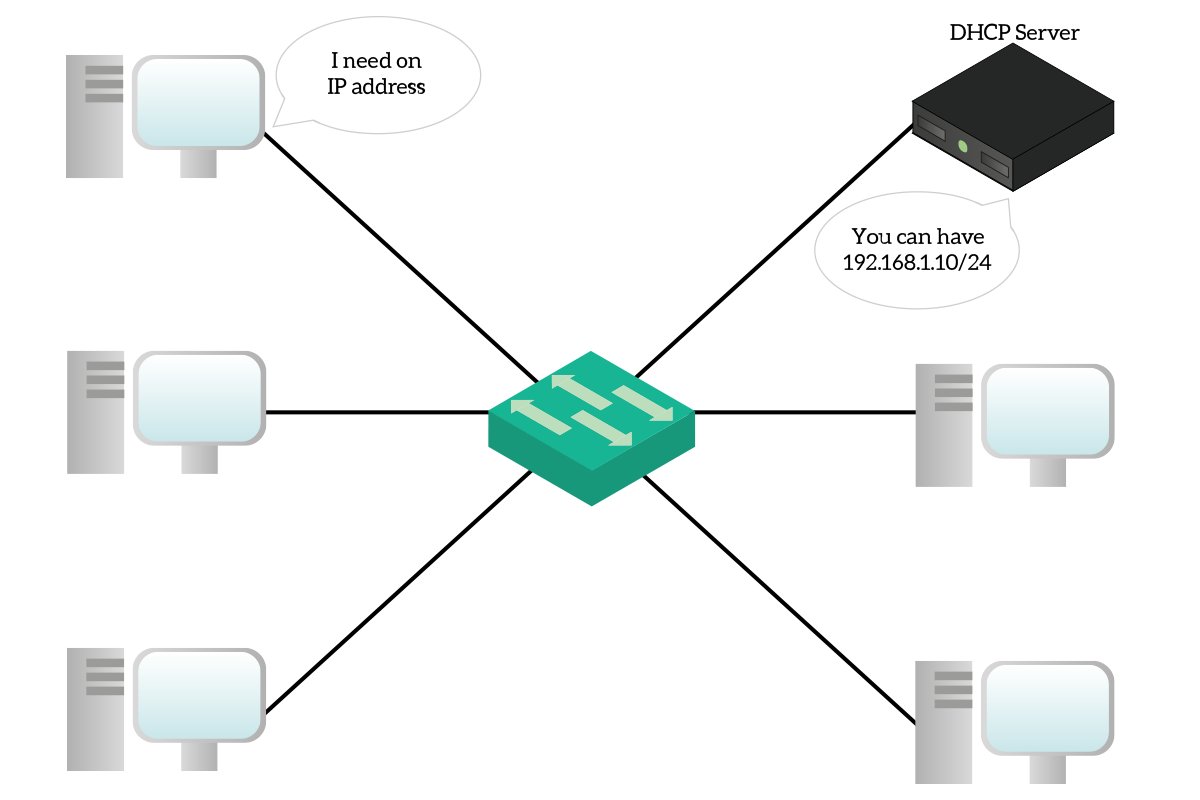
A computer configured to be a DHCP client (like almost any computer out-of-the-box) does not have an IP address, it does not know anything about the network it is connected to. So, it sends a message in the broadcast to check if there is a DHCP server on the network. If so, the DHCP server will assign an IP address, subnet mask, and default gateway to the client so that it will be able to interact in the network. This is a very flexible approach because if you move your PC from a network to another, the IP address changes automatically. Consequently, all PCs come with DHCP enabled by default as a factory setting.
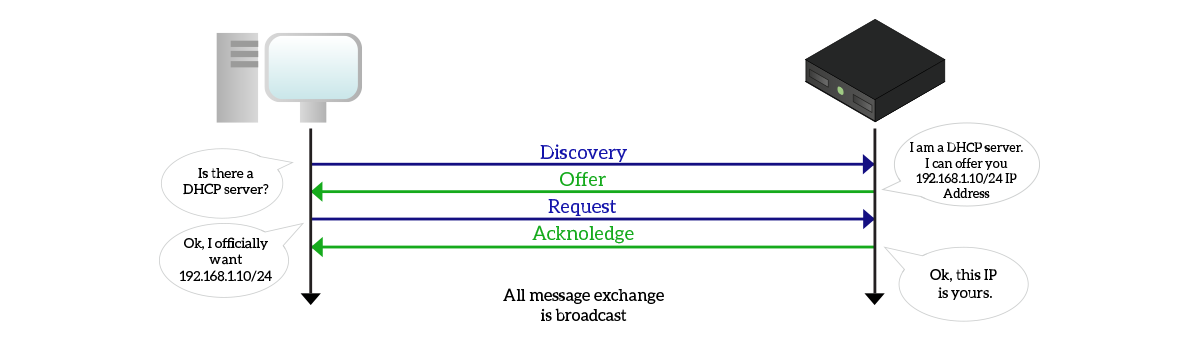
DHCP-obtained addresses do not last forever, they leased for a specific amount of time (generally 24 hours). In this time span, the DHCP server keeps track of the association of clients to IP addresses. To do that, it remembers the MAC address that issued the request. A client connecting to a network has to go through four steps in order to obtain an IP address.
First, the client sends a broadcast DHCP Discovery (D) to see if there is a server in the network willing to give an IP address. Any server in the network that wants to give an IP address to the client replies with a DHCP Offer (O), which is always sent in broadcast, containing an offered IP address. At this point, the clients officially requests the IP address offered by the server with a DHCP Request (R). That step (always broadcast= formalizes the request, as the client is not asking for any IP address now, it is asking for a specific IP address. Then, the server ping that IP address and if it has no response replies (always in broadcast) with a DHCP Acknowledgement (A). From now on, the client can use its new IP address until the lease expires.
By design, if more servers make an offer to the client, the client will make a Request for the Offer the client received first. Another interesting fact is that if the client has already an IP address can make a Discovery specifying the last IP address it had. Then, if that IP address is available (or if it is already assigned to the same client), the server will make an offer for that IP. Instead, if it is not available and the server is not authoritative, the server will timeout the discovery. If the server is authoritative, then it can explicitly deny the request. At this point the client will ask for a brand-new IP address.
DHCP comes from an old protocol named BOOTP, and all by itself, it can simply give us an IP address, which is not enough. We need to know at least a subnet mask and a default gateway address to effectively source traffic in the network. Other than that, we might also want to know the IP address of a name server in order to surf the Internet using website names. To obtain all this extra information, we must configure the DHCP server to give some options. An option is basically a numeric identifier associated with a value (generally an IP address). Tons of standard and proprietary DHCP options exist, but let’s check out the most important ones.
| ID | Size | Description |
|---|---|---|
| 1 | 4 bytes | Subnet mask for the client |
| 3 | 4 bytes+ | IP address of the default router |
| 4 | 4 bytes+ | IP address of one or more time servers (NTP) to use for time sync |
| 5 | 4 bytes+ | IP address of one or more DNS servers |
| 12 | 1 byte+ | Hostname (name of the client in the DNS infrastructure) |
| 15 | 1 byte+ | Domain name (name of the DNS zone the client is part of) |
Even if an IP address if 4 bytes long, you can see that almost all the options for IP addresses have a size of at least 4 bytes, but can have more. This is because the DHCP server can tell the client several IP addresses to be used for redundancy.
Now, suppose you are managing a network infrastructure for a large corporate environment. You should purchase a server to respond to DHCP requests for every subnet you have where you plan to put DHCP clients. Even if routers can be DHCP servers (just like at home!) this configuration adds a lot of administration burden and it is too decentralized. Instead, we want to have a centralized deployment, but how can clients contact a remote DHCP server if they do not even have an IP address? That’s where DHCP relay comes handy. DHCP relay is a configuration you do on a router in a subnet (typically it is the default gateway).
A router with that configuration will listen to DHCP requests, take them and put them in UDP segments destined to the remote DHCP server. Then, the DHCP server will send back replies to the router, that will re-open them and put the simple reply onto the network in broadcast, so that the user do not even know that the DHCP server is remote. This way, you can manage the IP addresses in your organization in a better way. Keeping track of addresses in your organization is the process of IPAM (IP Address Management). There are several tools that allow you to do IPAM and centralized DHCP on a single server.

As a golden rule, remember that server should always be in different subnets than clients. Clients should have DHCP-assigned addresses. Instead, addresses for servers and network devices should be manually assigned.
In case a client is unable to obtain an address from a DHCP server, it will automatically take an APIPA address from the 169.254.0.0/16 without default gateway. If your client has this address something bad happened. You basically are unable to communicate, and you should inspect your connection to the LAN and the DHCP server.
TFTP
TFTP stands for Trivial File Transfer Protocol, and it is a very simple (or trivial?) protocol used to transfer files. We put this protocol in the selection of protocols for the network because of several reasons. First, it is the one mainly used to transfer files between networking devices. Second, it is very useful during the initial setup of those devices and VoIP phones rely on it. TFTP is mainly used to download logs or to push the operating system and/or the configuration to a remote network device, such as a switch or a router.
Unlike FTP, which works with two separate TCP channels (one for control, and one for data). TFTP implements control and data over a single channel, which is UDP-based and uses port 69 (server-side). Each segment sent is to be acknowledged, making it slower than FTP which leverages the TCP acknowledgment system. Another important difference is that you can use the same FTP session to move multiple files, one after the other, but with TFTP you can’t. A TFTP session is related to a file transfer and it is closed once the transfer end. As a result, transferring multiple files will require multiple TFTP sessions. No secure version of TFTP currently exists.
Dynamic Routing
Modern networks are huge, connecting millions of devices. These devices are organized into subnets, and each subnet must be able to reach any other remote subnet. In order to make this possible, routers must know where to send traffic. For every single subnet they know, they must know the way traffic will have to take to reach that subnet. This information is stored in a specific part of the memory called routing table.
We can manually create static entries to put into the routing table. This is certainly an option for small environments with just a few subnets. However, in large enterprises or service providers, you will have to deal with hundreds or even thousands of subnets. Having a static entry for each of them translates into a huge upfront effort. Maintaining becomes an even bigger effort: a lot of subnets mean a lot of routers. As a result, every time you do any change on any subnet, you must update all routers. Moreover, if a link dies in the path all traffic that was statically configured to go over that path will be lost until the administrator modifies the routing table on at least some of the routers. What if we could automate this? Well, with dynamic routing we can.
Dynamic routing means that routers autonomously keep their routing table up-to-date. To do that, they rely on each other by exchanging some information. To exchange routing information, we rely on specific routing protocols. Each protocol uses its own data format, managed by an algorithm running on the router. To exchange information, two routers must speak with the same protocol. Instead, if we want to send the information coming from a protocol to another protocol we need a router running both protocol to do that. This process, called redistribution, is a CCNP topic and we won’t go deeper on that.
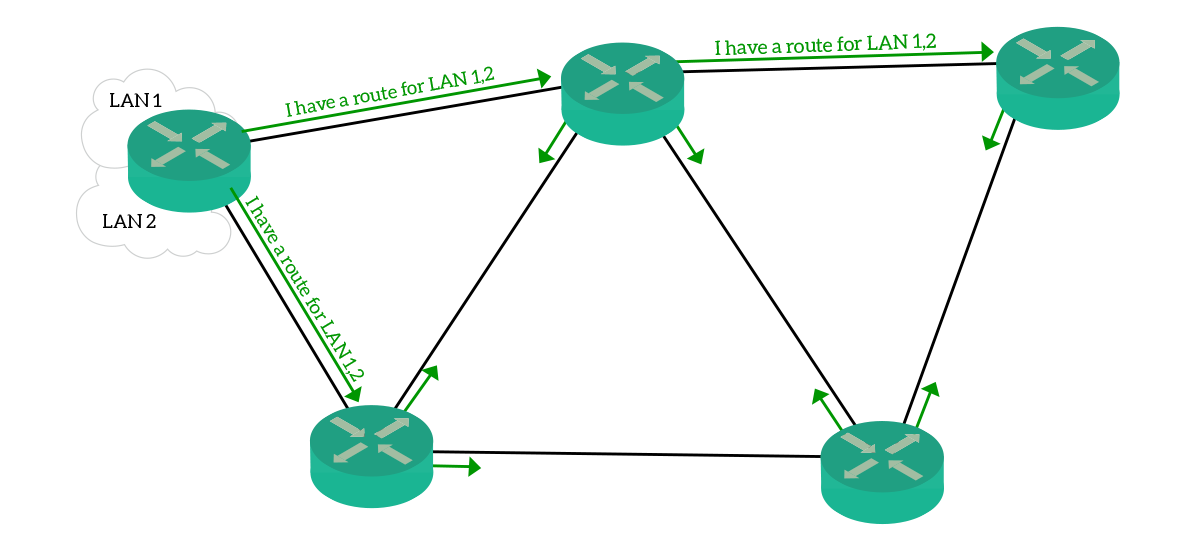
There are several ways to categorize routing protocols. One of them is based on the type of information they exchange. With this categorization, three types of routing protocols exist:
- Distance Vector – This is the simpler type of protocol. Routers exchange routes associated with a value called distance, then the receiving router uses the route with the best (lower) distance. An example message would be
I can get to 10.1.1.0/24 in 4 hops. Information exchanged is received by a router, manipulated (distance is increased) and then send to other routers. In this family of protocols we can find Routing Information Protocol (RIP) and Enhanced Interior Gateway Protocol (EIGRP). - Link State – This family of protocol is much more advanced and resource-intensive. This is because these protocols maintain database instances and exchange records. Instead of exchanging information about routes, they exchange information about links, like
I am Router 1, and I am connected to Router 2. These messages are forwarded the way they are to all routers running the protocol, without any manipulation. Then, every router will be able to create a map of the network based on that information. With that picture in mind, the router will create its own routing table. This protocol family reacts to network changes much faster than Distance Vector. In this family, we can find Open Short Path First (OSPF) and Intermediate System to Intermediate System (IS-IS). - Path Vector – This family contains a single protocol, the Border Gateway Protocol (BGP). This protocol is used to exchange routing information between networks managed by different entities. You can use BGP to exchange information with your Internet provider, and providers talks to one another using BGP. This is the only protocol for this purpose, and it defines the way this category works. BGP counts the distance based on the number of networks (and not routers) the traffic as to go through. BGP is out of scope for the CCNA course, as it is part of the CCNP curriculum.
Conclusion
With this article, we discovered some of the most important protocols that allow us to use the Internet the way we do, without even noticing. We have also reached the top of the OSI. Now, we learned everything we need to start diving into the field. Take a moment to review the articles in the CCNA course up to this one. After that, we will go to get our hands on network devices, configuring switches and routers!

